[Eclipse] Pleiades All in One の Windows 8 フォント設定対応

Pleiades All in One の自動デフォルト設定で Windows 8 の場合にフォント設定が動作していなかったため対応しました。また、下記の方がブログに記載されている件に関してソースを確認したところ、プロパティー・ファイルの編集で一部の文字が変換されないようなので作者の方へバグ報告し、別のプラグインに変更して対応しました。
プロパティファイルで「×」が文字化けする - 眩しいサインを見ただろう
http://mabushiisign.hatenablog.jp/entry/2012/11/20/010243
変更内容
4.2.1.v20121123
- Limy Eclipse プラグインに含まれるプロパティー・エディターに "×" などの 0x100 以下の文字が変換されない問題があるため、Properties Editor (http://propedit.sourceforge.jp) に変更。
- Properties Editor 拡張プラグインの Java エディター上でのプロパティーのホバー表示、プロパティー参照箇所へのジャンプ機能を追加。
- Tomcat 更新
Eclipse Pleiades All in One 4.2 Juno ダウンロード
4.2.1.v20121118
パフォーマンス比較 Cassandra、Mongodb、SQLite、H2、MySQL、Postgres

下記のようなシステムでパフォーマンスが良さげな SQLite を使用予定ですが、もっと速いものが無いか確認のため他のデータベースのパフォーマンスを計測してみました。SQL 利用前提ですが、NoSQL が圧倒的な性能を出す場合は検討する必要があるので KVS も確認しました。
- データ件数は 1 億件程度、JDBC SQL 利用可能
- INSERT、UPDATE はバッチ
- SELECT は主キーアクセス性能を重視
- 将来スケールアウトのための分散はありえるが、スタンドアロンで遅いのはだめ
データベースのパフォーマンス比較
計測したデータベース
| データベース名 | タイプ | 形態 | 評判 | 計測についての備考 |
|---|---|---|---|---|
| SQLite | RDB | 組み込み ※2 | おもちゃ、Android標準 | JDBC操作 ※1 |
| H2 | RDB | 組み込み ※2 | 組み込み最速 | JDBC操作 ※1 |
| Derby | RDB | 組み込み ※2 | Java標準で付属 | JDBC操作 ※1 |
| EHCache | KVS | 組み込み ※2 | OSCacheと2大巨頭 | 1万件ごとにディスク書き込み設定 |
| Redis(Jedis) | KVS | サーバー ※4 | 爆速 | Jedis API 操作 |
| Mongodb | KVS | サーバー ※4 | 高パフォーマンス | Mongodb 標準 API 操作 ※3 |
| Cassandra | KVS | サーバー | 大手導入事例多数、廃止も多数 | JDBC操作 (AutoCommit のみ可能) |
| MySQL(MyISAM) | RDB | サーバー | サーバ型非トランザクションRDB最速 | JDBC操作 ※1 |
| MySQL(InnoDB) | RDB | サーバー | サーバ型トランザクションRDB最速 | JDBC操作 ※1 |
| PostgreSQL | RDB | サーバー | MySQLと異なりGPLじゃない | JDBC操作 ※1 |
※1 JDBC 操作に関して INSERT は 1 万件ごとにコミット、SELECT は主キー指定で 1 件ずつ全件取得
※2 組み込みモード (ローカルファイル永続化) のみ計測、インメモリモードやサーバーモードは未計測
※3 全 INSERT 後の ensureIndex によるインデックス作成時間が計測結果に含まれる
※4 遅延書き込み (非同期書き込み) *1
計測結果
環境 CPU Core2 Duo 2GH 2GHz*2、メモリ 4GB、Windows XP 32bit*3、HDD (TOSHIBA MK8052GSX)*4、しょぼめのノートパソコン
データ 主キー:数値、値:文字列、レコード長:約 200 byte
スレッド数 1

線形的増加と指数関数的増加、臨界点
データベースの処理数に対する処理時間は、上記結果の MySQL に見られるような線形的増加 (リニア、直線的) に増加するパターンと、Cassandra のように指数関数的 (雪ダルマ式) に増大するパターンがあります。また、線形的増加から指数関数的増加に移行する臨界点や動作不能になる臨界点がある場合が多いです。1 万件での処理時間はこうだから 1 億件の予想処理時間はその 1 万倍というような情報をたまに見かけますが、件数が増大するほど線形的増加ではないほうが多いと思います。
SQLite が予想以上に他を圧倒し高速

SQLite が INSERT、SELECT とも予想以上に他を圧倒し高速でした。計測結果に示すとおり 1 億件程度のデータ (データファイルサイズは 1.8 GB でした) なら大丈夫そうです。H2 のサイトに H2 が最速とするパフォーマンス比較 (H2) がありますが SQLite はトランザクションがテストされていないという理由で比較されていません。ちなみに実際には SQLite はトランザクションをサポートしていて、テストに関しても SQLite 本体コード 6万7000行 に対しテストコードは 4567万8000行 (publickey) だそうです。古い情報ですが、SQLiteを使うべき10の理由と5つのデメリット (CAP-LAB テクニカル) が色々参考になります。
SSD で試してみたところ、1 億件 INSERT 647秒、1 億回 SELECT 383秒 でした。さすがに速い。SSD 環境は CPU i5 2.4GH、メモリ 8GB、Windows 7 64bit*5、SSD (TOSHIBA THNSNC128GMMJ)*6、これもノートパソコンです。
件数が増えると EHCache が想定以上に遅い

EHCache は 1 万件取得で最速ですが、件数が増えると組み込み RDB の SQLite や H2 より遅いのは良い?にしても、クライアント・サーバー型 KVS の Mongodb や Redis より総合的に少し遅いのは予想外でした。overflowToDisk の設定にもよると思いますが、知らずに H2 や Mongodb のキャッシュとして EHCache を使ってまいそうです。すべてディスクに永続化するように設定していたのですが、100万件テストでは登録したデータを取得しようとしたときに欠落している場合があるため計測しませんでした。ところでロゴを見て気づいたのですが EHCache が回文になっているのを今初めて知りました。
Mongodb がクライアント・サーバー型としては登録性能に優れている

最速の SQLite と比較すると登録は 6 倍かかり、取得は 20 倍かかりますが、クライアント・サーバー型としては最も登録性能に優れています。ただし、分散環境ではデータがときどき消える、マルチコアでスケールしない (InfoQ)、などに注意する必要があります。もちろん、これらの問題は将来解消されるかもしれません。

NoSQL、KVS が終焉

NoSQL が終焉したと言われて久しいですが、Google のインフラ基盤や Facebook の HBase (Hadoop) で HBase (Hadoop データベース)*7 がバリバリ使われていて、Mixi では永続化機能付き memcached とも言える TokyoTyrant が使用され、DeNA では MySQL に HandlerSocket を組み込み NoSQL を実現しています。必要な場面があるので今後も NoSQL や KVS が無くなることはなく、逆に RDB も衰退することはありません。Twitter は今でも MySQL + memcached ですし、GAE では MySQL も用意されています。また、NoSQL に対して SQL が遅いというアンチテーゼとして、Postgres の設計者による分散インメモリ RDB の VoltDB が登場しています。
業務システムから見ると SQL はそのままでスケールアウトしたいという要望に単純な NoSQL や KVS は合致しません。元々 RDB がスケールアウトによりリニアにスケールしない問題や耐障害性を解決するために Google の BigTable などにインスパイアされ登場したのが分散 KVS ですが、現在は RDB に NoSQL や KVS の要素が取り込まれています。例えば、MySQL 5.6 では memcached や HandlerSoclet などの概念が取り込まれ SQL なしで高速アクセス可能になっています。また MySQL Cluster や Oracle Exadata は分散 KVS と同じようにリニアにスケールアウト可能になっており、Postgres も 32 コア CPU 対応などスケールアップ可能になっています。
追加 2012/10/19
計測結果についての補足
計測結果はあくまでも私が必要な環境と条件の計測結果であり、id:matsumoto_r さんがおっしゃられているとおりデータベースそのものの優劣を示しているものではありません。並行アクセスしたらとか、設定変えたらとか、たくさんご意見いただきましたが、もちろん、負荷条件を変えたりそれぞれ環境に合わせてチューニングすれば結果は変わると思います。今回の想定システムでは並行アクセスはほぼ発生せず意味がないのでマルチスレッドでの計測はせず、シングルスレッドでのデータ永続化の基本性能を確認するために実施しました。並行処理が得意(前提)とされるデータベースをシングル構成で計測に追加したのは差を確認するためです。並行性能の情報はたくさん公開されていると思いますが、ご自分の環境に合う方法で計測していただければと思います。
なお、ソフトウェアやドライバはすべて最新安定版、設定はデフォルトです。ただし、全データのディスク同期が前提の計測であるため、EHCache はインメモリではなくディスク永続化モードです。ちなみに SQLite はもう少し触ってみたところ Beta 版にすると 20% 高速化、非同期モードにするとさらに 10% 高速化しました。
計測になぜ Oracle が含まれてないの?
私は臆病者なので良い結果を出さないと Oracle に怒られる気がするからです。OTN ライセンスに下記の条項が含まれています。
オラクルの事前承諾なく、プログラムのベンチマークテストの結果を開示すること。
OTN開発者ライセンス
蛇足ですが、DB2 は設定を完璧にして最新パッチをあてて最高性能を出さないと怒られるかもしれません。
(A) ベンチマーク・テストで使用した方法 (例えば、ハードウェアおよびソフトウェアのセットアップ、導入手順および構成ファイル) を公開し、
SLA - L-JWOG-6K4JSQ
(B) 「プログラム」に対する IBM または IBM 製品を提供する第三者 (以下「第三者」といいます。) から提供される最新の適用可能な更新、パッチ、修正が適用された所定の稼働環境で 「プログラム」を実行してベンチマーク・テストを行い
(C) 「プログラム」の資料ならびに IBM がサポートする「プログラム」用の Web サイトで提供されているすべてのパフォーマンス・チューニングおよび最良の方法に従うこと
計測ソース*8
今回の計測対象のメインとなる JDBC のソースはこちらになります。INSERT のあとの SELECT なのでキャッシュ云々の話もありますが、それも含めて各データソースに対して同じ操作をしています。SQLite のみ Class.forName しているのはドライバがサービスプロバイダーフレームワークに対応していないためです。(bitbucket リポジトリの最新ソースでは 2012/09 対応)
package test; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.Statement; import org.junit.After; import org.junit.Test; public class JdbcTest { @Test public void sqlite() throws Exception { Class.forName("org.sqlite.JDBC"); con = DriverManager.getConnection("jdbc:sqlite:test.sqlite3"); Statement st = con.createStatement(); executeUpdate(st, "drop table if exists person"); executeUpdate(st, "create table person (id integer primary key, name string)"); executeQuery(); } @Test public void h2() throws Exception { con = DriverManager.getConnection("jdbc:h2:testh2", "sa", ""); Statement st = con.createStatement(); executeUpdate(st, "drop table if exists person"); executeUpdate(st, "create table person (id integer primary key, name varchar)"); executeQuery(); } @Test public void derby() throws Exception { con = DriverManager.getConnection("jdbc:derby:derby;create=true"); Statement st = con.createStatement(); executeUpdate(st, "drop table person"); executeUpdate(st, "create table person (id int primary key, name varchar(200))"); executeQuery(); } @Test public void mysql_myisam() throws Exception { mysql("MyISAM"); } @Test public void mysql_innodb() throws Exception { mysql("InnoDB"); } private void mysql(String engine) throws Exception { con = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", ""); Statement st = con.createStatement(); executeUpdate(st, "drop table if exists person"); executeUpdate(st, "create table person (id integer primary key, name varchar(200)) engine = " + engine); executeQuery(con.getMetaData().getDatabaseProductName() + "(" + engine + ")"); } @Test public void postgres() throws Exception { con = DriverManager.getConnection("jdbc:postgresql:postgres", "postgres", "postgres"); Statement st = con.createStatement(); executeUpdate(st, "drop table if exists person"); executeUpdate(st, "create table person (id integer primary key, name varchar)"); executeQuery(); } @Test public void cassandra() throws Exception { con = DriverManager.getConnection("jdbc:cassandra://localhost:9160/test"); Statement st = con.createStatement(); executeUpdate(st, "drop table person"); executeUpdate(st, "create table person (id int primary key, name text)"); executeQuery(); } // 共通メンバー ------------------------------------------- private Connection con; private static final int COUNT = 10000 * 10; private static final String DATA = "12345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890"; @After public void after() throws Exception { if (con != null) { con.close(); } } private void executeUpdate(Statement st, String sql) { try { st.executeUpdate(sql); } catch (Exception e) { System.out.println(e.toString()); } } private void executeQuery() throws Exception { executeQuery(con.getMetaData().getDatabaseProductName()); } private void executeQuery(String databaseName) throws Exception { boolean isCassandra = databaseName.contains("Cassandra"); boolean isAutoCommit = isCassandra; System.out.printf("%-14s", databaseName); if (!isAutoCommit) { con.setAutoCommit(false); } long insertStart = System.currentTimeMillis(); PreparedStatement insertPs = con.prepareStatement("insert into person (id, name) values(?, '" + DATA + "')"); for (int i = 0; i < COUNT; i++) { insertPs.setInt(1, i); insertPs.executeUpdate(); if (!isAutoCommit && i % 10000 == 0) { con.commit(); } } if (!isAutoCommit) { con.commit(); } double insertSec = (double) (System.currentTimeMillis() - insertStart) / 1000; long selectStart = System.currentTimeMillis(); PreparedStatement selectPs = con.prepareStatement("select * from person where id = ?"); for (int i = 0; i < COUNT; i++) { selectPs.setInt(1, i); selectPs.executeQuery().next(); } double selectSec = (double) (System.currentTimeMillis() - selectStart) / 1000; String countSql = "select count(1) from person"; if (isCassandra) { countSql += " limit 100000000"; } ResultSet rs = con.createStatement().executeQuery(countSql); rs.next(); logProcessTime(rs.getInt(1), insertSec, selectSec); } private void logProcessTime(long count, double insertSec, double selectSec) { System.out.printf("%4d万件 ", count / 10000); System.out.printf("%7.2f秒 ", insertSec); System.out.printf("%7.2f秒", selectSec); System.out.println(); } }
黒背景 Eclipse Dark Juno でクールにキメる
重要なのは開発手法でも言語でもフレームワークでもない。クールにキメて今日から君もモテリプス。

Black Eclipse
上のイメージの黒を基調としたダーク系 Eclipse に必要なプラグインと設定方法です。
必要なプラグイン
- Eclipse Color Theme プラグイン / 色テーマ - Pleiades All in One 同梱
- Dark Juno - zip ファイルをダウンロード
- Moeclipse - Java エディター背景画像設定
- eclipse.org Lightweight CSS エディター - Eclipse マーケットプレースから CSS で検索
- eclipse.org CSS スパイ - (必須ではない) Eclipse マーケットプレースから CSS で検索
設定方法
一般 > 外観 > 色テーマ で「Pastel」を選択。(どれでもいい)
一般 > 外観 のテーマで「Dark Juno」を選択。
Lightweight CSS エディターでビュータイトルの font-size 12 を 9 に変更。
これは Dark Juno プラグインに含まれる CSS ファイルを直接書き換えるのと同じです。

Moeclipse で Java エディター背景に適当な画像を設定

CSS スパイ。クイック・アクセスから CSS を入力し、CSS スパイを開く で開きます。
ウィジェットを選択すると、実際の部品が赤枠で囲まれ、プロパティーを変更すると見た目を確認できます。
このプラグインは必須ではありませんが、CSS を細かくカスタマイズする場合は便利です。

Stylish Eclipse
黒系じゃなく普通の感じでいいけど、Eclipse Juno のデフォルト・テーマはビューの間が広くてちょっとかっこ悪い、かといって、XP テーマに戻すのもなんだかあれ。という場合は Eclipse 4 Chrome Theme がお勧めです。設定画面からビュー間を調整できます。ちなみに Chrome という名前はブラウザの Google Chrome は無関係です。
必要なプラグイン
設定方法
一般 > 外観 > Chrome テーマ の右上の矢印からのプリセットが選択できます。ビューの幅を狭くするにはマニュアルを選択し、サッシュ幅を最小にします。細いサッシュを選択すると、Eclipse 3 系と同じような外観になります。

Eclipse Juno デフォルト・テーマ

Chrome テーマ > Chrome Modern - マニュアル、サッシュ幅最小

Chrome テーマ > Hello Kitty - マニュアル、サッシュ幅最小

Chrome テーマ > Chrome Modern - 細いサッシュ

Chrome Theme の CSS は Xtend で動的に生成されているため、Lightweight CSS エディターで編集することはできません。
フォントにこだわる
無料公開された Source Code Pro や MeiryoKe_Console を使うとさらにモテリプスだ。
Source Code Pro
[速報] ソースコードを表示するためのフォント「Source Code Pro」をアドビがオープンソースで無料公開
MeiryoKe_Console
dai1741's blog: Windows 7のEclipseのフォントをきれいなものにする
Play フレームワークの scala.html などの文字エンコード自動判別を無効化

Eclipse には JSP や HTML の文字エンコードを内容により自動的に判別する機能があります。ただ、これは JSP に include する断片ファイルや Play 2.0 フレームワークの scala.html のように meta charset 指定などが無い部分的な HTML を持つ場合、UTF-8 が Shift_JIS と誤って判定され文字化けが発生します。
回避策として、下記の方が記載されているように、ファイルごとに文字エンコードを指定すれば対応可能ですがこれは面倒です。また、eclipse.ini に -Duser.language=en を指定すれば回避できますが、これは日時表記が英語になる問題があります。
htmlを開くと文字化けするとき - newta(にゅーた)の日記
原因は Dead Zone に記載されているように WST の日本語向けの自動判別のバグで、Eclipse 3.3 以降から現在の Juno でも改修されていません。
http://blog.goo.ne.jp/atlanto/e/f9c32302055b47f3521df3ee0967992d
Pleiades AOP で実行時にバグ修正: HTML 判別を無効化
そもそも内容から完全に文字コードを判別することはできないので Pleiades AOP で動的に無効化します。pleiades-config.xml に下記の AOP 定義を追加し -clean 起動することで回避できます。ちなみに meta タグに charset 指定がある場合はこの AOP 定義に関係なくそれが優先して使用されます。この AOP 定義は次回リリースの Pleiades に組み込む予定です。
plugins/jp.sourceforge.mergedoc.pleiades/conf/pleiades-config.xml
<!-- HTML 日本語文字エンコーディング自動判別無効化 (after) --> <pointCut editPoint="execution" timing="after"> <advice><![CDATA[ return false; ]]></advice> <jointPoint className="org.eclipse.wst.html.core.internal.contenttype.EncodingGuesser" methodName="canGuess"/> </pointCut>
IDEA に Pleiades 日本語化プラグインを挿してみた
最新の IntelliJ や Android Studio などを日本語化する場合は、http://qiita.com/cypher256/items/a87179fbe8dd7f63ec4e を参照してください。
高速統合開発環境 IntelliJ IDEA に Pleiades を適用してみました。
ちょっとだけ日本語になりました。
やり方
/plugins に pleiades.zip の plugins/jp.sourceforge.mergedoc.pleiades を配置 /bin/idea.exe.vmoptions の末尾に -javaagent 追加
-Xms128m
-Xmx512m
-XX:MaxPermSize=250m
-XX:ReservedCodeCacheSize=64m
-ea
-javaagent:../plugins/jp.sourceforge.mergedoc.pleiades/pleiades.jar

フリーズ不具合修正と eclipse.ini の設定値
E4 に対する Pleiades 本体の不具合を修正し、Pleiades All in One にも反映しました。
Pleiades All in One の eclipse.ini メモリ設定
以下、ダウンロードページに記載したものを転載します。
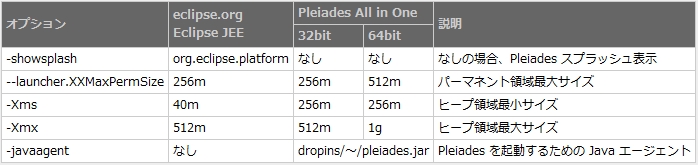
ヒープの最小 Xms と最大 Xmx は同じにしたほういいの?
サーバーで利用する Sun Server VM や JRockit は同じサイズを指定して GC 回数を減らすことが推奨されています。ただし、これは GC の 1 回あたりの負荷が高くなり、コンカレント GC であってもクライアント GUI アプリケーションなどの場合は操作がブロックされるように感じられる場合があります。IBM JVM では、このような GC 負荷を減らすため -Xms にはアプリケーションで必要な最小サイズを指定することが推奨されています。Eclipse を実行する環境としても JVM の種類に関わらず -Xms には適切な最小サイズを指定することをお勧めします。
パーマネント領域の指定について
-XX:MaxPermSize ではなく --launcher.XXMaxPermSize で指定しているのは、-XX:MaxPermSize が Sun JVM の拡張オプションであり、それ以外の JVM では起動できない場合があるためです。 Eclipse ではその問題を回避するために、--launcher.XXMaxPermSize が指定された場合、JVM ランチャーである eclipse.exe が Sun JVM に -XX:MaxPermSize を渡し、それ以外の JVM には何も渡しません。IBM JVM はパーマネント領域は自動制御されるため指定する必要がなく、JRockit ではパーマネント領域ではなくネイティブ領域 (物理メモリ - ヒープ) にクラス情報が格納されます。
-XX:MaxPermSize を指定しないと起動しない場合があるのはなぜ?
前述の問題を eclipse.exe が解決するため、基本的には -XX:MaxPermSize を指定してはいけません。基本的にというのは、過去に少なくとも 2 つの問題があり、そのような場合は -XX:MaxPermSize の指定が必要な場合があります。1 つは Eclipse 3.3.0 が JVM に -XX:MaxPermSize を渡さないバグがありました。2 つ目は Sun が Oracle に買収されたときに、VM が保持する会社名文字列を Sun から Oracle に変更し (内部仕様変更として外部には告知されなかった)、不運にも eclipse.exe はこれを文字列判定していたため問題が発生していました。この問題は Java 6 update 21 で修正されています。